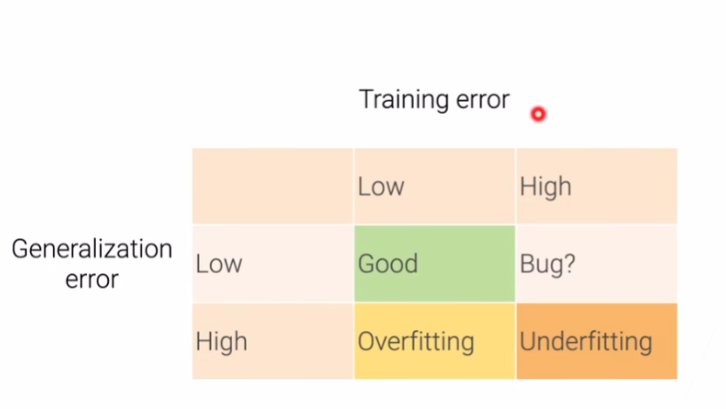
4.2 过拟合和欠拟合
- 训练误差:对于训练数据上的误差
- 泛化误差:对于新数据的误差
- 例子:同学都做真题,但是真题做的好并不代表做考卷做的好;A同学死记硬背,做真题很好,但是做考卷很差;学生B理解解题思路,因此做考卷可能很好
 ![]
![]
- 模型的复杂度
- 概念:拟合不同函数的能力
- 在一个算法的家族下(决策树/神经网络),以下两个因素决定了模型的复杂度
- 超参数的个数
- 每个参数可以取到的值
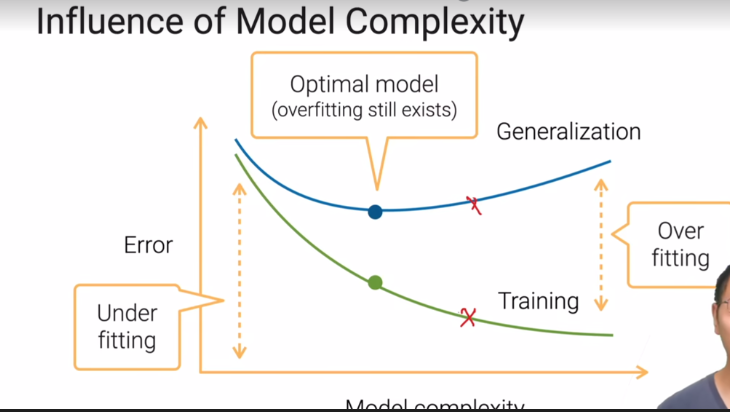
- 当模型相对简单的时候,训练和泛化误差偏高;当模型逐渐复杂,模型会过拟合;最好的地方是泛化误差最低的时候
- 例子:决策树
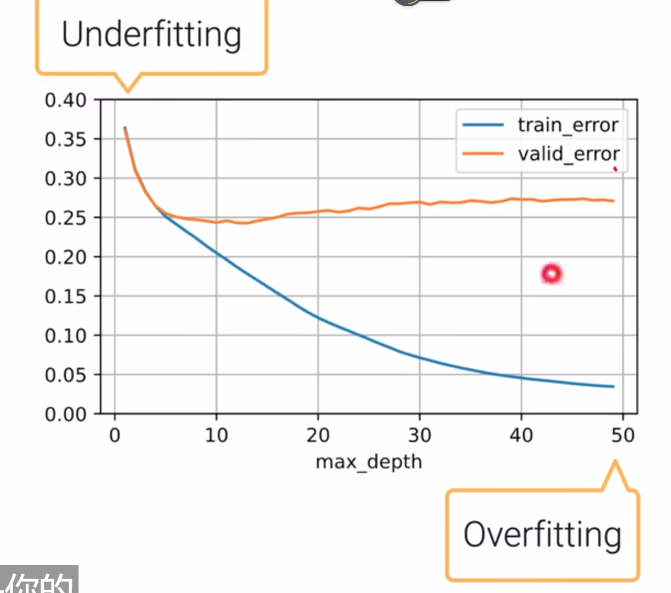
- 横坐标是决策树的深度,我们需要找到泛化误差最低的位置,此时对应的决策树深度是最优的
- 数据复杂度
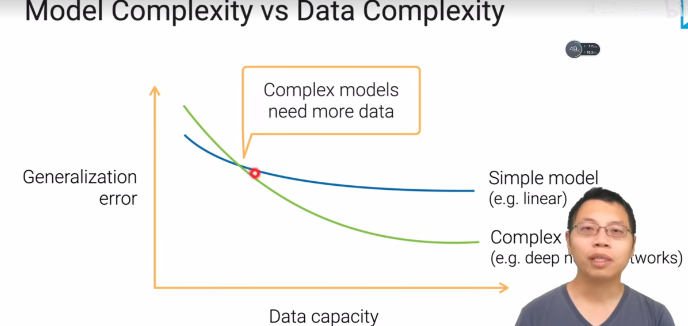
- 当模型复杂度不变,增加数据复杂度,模型泛化能力通常会下降;当选择复杂模型时候,一开始数据量很少,而模型参数很多,因此过拟合;随着数据慢慢增多,复杂度和模型相匹配,此时泛化能力提高
- 结论:
- 当数据集比较小的时候,可以选用小型的模型,而不需要神经网络;当数据集比价复杂,可以用神经网络
- 考虑商业指标:延迟
- 选择好模型之后,调节超参数去看泛化误差哪个可以最小;加正则项调节可学习参数的范围
References
4.2 过拟合和欠拟合【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili